现代计算机体系结构
存储架构
现代计算机使用冯诺依曼架构,为缓解计算单元到存储单元巨大的速度差异使用分级存储的方组织多层级不同速度的内存,因而有了 cache。ram 和 ssd 或者 hdd 等多种。通常计算单元也就是 CPU 从内存中获取数据并缓存在 Cache 之中,在这个过程中由 MMU(Memory Manager Unit)进行控制,通过内存总线 (Memory Bus,这也是 IO 数据传输通路的一部分)。MMU 同时负责将内存搬运到 CPU 或者将其他设备传输到内存,同时负责将虚拟的内存地址映射到实际的物理地址。
正常数据从外部设备如磁盘搬运的过程,需要从磁盘到 CPU 再到内存,出于性能优化和避免 CPU 阻塞考虑,可以使用 DMA(Direct Memory Access) 实现直接从数据搬运到内存的过程,而不再需要频繁的 CPU 参与

CPU 和 GPU
GPU 和 CPU 均具有计算能力,但是他们所擅长的任务不同,CPU 擅长复杂的逻辑运算,而 GPU 更擅长多数据批量计算,为此他们都具有独立的内存和 MMU 模块,在 GPU 中对应的存储结构为 VRAM(Video RAM)。当 CPU 和 GPU 发生数据交互时,需要双方遵循一定的协议进行数据传输,进而演变出如今的 PCI-E 协议,其设计类似之前的总线结构,提供了不同设备传输数据的协议规范
NUMA
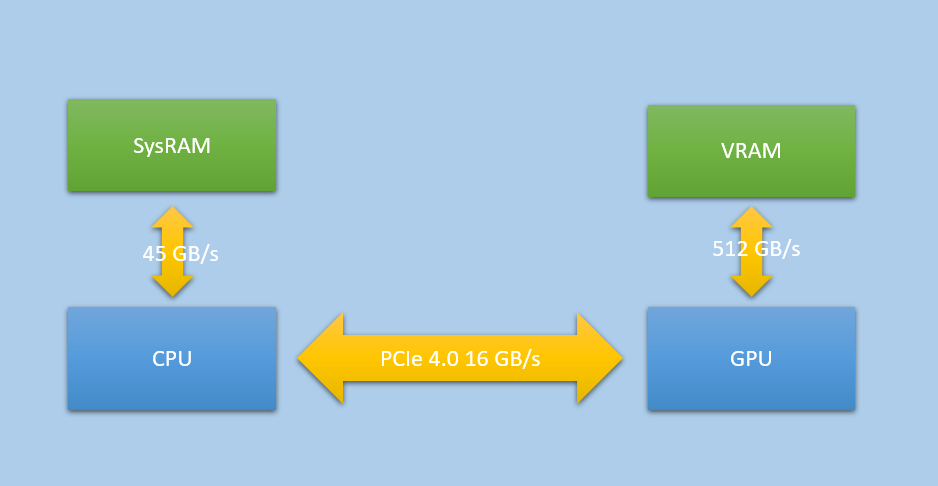
我们使用具有独立显卡的 PC 机,就是如图所示的 NUMA 架构,其特征是 CPU 和 GPU 具有独立的内存和 MMU,并通过 PCI-E 协议进行数据交换。在现代 GPU 中往往具有独立的数据拷贝引擎专门负责数据的传输,类似上文提到的 DMA。
除了DMA数据传输CPU-GPU 内存间数据交互,当CPU直接调用指令读取GPU内存数据时,数据会经历类似磁盘访存的过程,数据先传递到CPU,在存储到系统内存中,因而在这个过程中Cache会发挥一定的作用。如将数据写入到GPU或者将GPU数据读取回内存。
虽然现在CPU已经实现多条指令并行执行的多核流水线,但是对于单条指令而言其只能做一件事情,如访存、写入和计算等

UMA
UMA 架构指的是将 CPU 的 RAM 和 GPU 的 VRAM 进行合并,实现如下图所示的架构。其常见于集成显卡和 CPU、家用游戏机如 PS4、Xbox 等,不同设备间具有统一的内存和 MMU 管理。

UMA/NUMA
UMA 的优势
- CPU-GPU 甚至其他设备可以直接互相访问数据,提升了数据访问速度(不再需要从 GPU 拷贝到系统内存)实现更高层次的协同。
- 避免 CPU、GPU 两处内存的管理控制,降低了开发和维护难度
UMA 的局限性
UMA 并不是万能的,并且如果缺乏良好的软件设计和硬件支持,会效率低下甚至会发生错误。
首先,UMA 并不能解决 CPU 读取 GPU 数据慢的问题。因为,这个问题本身不全部是数据传输的问题,更多的是基于 CPU-GPU异步的架构设计所造成的。由于 GPU 追求高吞吐率,因而实际运行的指令可能存在多帧堆叠的现象,因而当 CPU 希望从 GPU 获取数据时,其数据对应的内存首先需要进行同步,完成现有提交的流水线计算任务,然后才能够执行数据传输,由 CPU 访问获取。
其次,如果硬件本身设计并不支持统一的 Cache 控制,也就是说每个设备具有独立的 cache 管理。当数据期望读取时,错误地读取了设备 cache 中的数据而不是实际内存中的数据,会发生错误。另外,当如果期望写入内存中,但是对应的 cache 存在部分数据没有刷新到内存,也会造成错误。同时,有人会说那我不用 cache,直接使用内存不就解决问题了吗。如果读取写入若不依赖 cache,直接写入内存,基于现代存储单元层级化的体系,会造成的频繁且效率底下 IO 传输,大大降低程序的执行效率。
NUMA 性能和成本
UMA 除了解决数据协同问题以外,本身并不能解决带宽带来的问题,因而如果性能瓶颈发生在像素处理的带宽层次,则 NUMA 更为合适
在 NUMA 架构中,图形处理设备往往使用 GDDR(图形专用内存)有的也称为 VRAM(Video RAM)而 CPU 则使用 DDR(通用内存),这使得 GPU 内部可以获得更大的带宽(提供更多的 bit 传输通路,便于 SIMD 访问)和更高的时钟频率,进而获得更好的性能。相对的其成本也会更高,并且发热量也会更大。
| 厂商硬件 | 带宽 |
|---|---|
| Intel Alder Lake CPU | 50-70GB/s |
| AMD RX6800 | 512GB/s |
| NVIDAI RTX 3090 | 936GB/s |
NUMA 通信成本
| Version | Introduced | Throughput1 | ||||
|---|---|---|---|---|---|---|
| x1 | x2 | x4 | x8 | x16 | ||
| 1.0 | 2003 | 0.250GB/s | 0.500 GB/s | 1.000 GB/s | 2.000 GB/s | 4.000 GB/s |
| 2.0 | 2007 | 0.500 GB/s| | 1.000 GB/s| | 2.000 GB/s | 4.000 GB/s | 8.000 GB/s |
| 3.0 | 2010 | 0.985 GB/s | 1.969 GB/s | 3.938 GB/s | 7.877 GB/s | 15.754 GB/s |
| 4.0 | 2017 | 1.969 GB/s | 3.938 GB/s | 7.877 GB/s | 15.754 GB/s | 31.508 GB/s |
| 5.0 | 2019 | 3.938 GB/s | 7.877 GB/s | 15.754 GB/s | 31.508 GB/s | 63.015 GB/s |
| 6.0 | 2022 | 7.563 GB/s | 15.125 GB/s | 30.250 GB/s | 60.500 GB/s | 121.000 GB/s |
| 7.0 | 2025 (planned) | 15.125 GB/s | 30.250 GB/s | 60.500 GB/s | 121.000 GB/s | 242.000 GB/s |